A Brief History of the Pull Request
I’m a curious person by nature. Any time I pick up a new hobby, or get invested in a TV show, or start using some new (digital) tools, the first thing I do is read everything I can find about it. How does x1 work? Who came up with it? Why is it called that? How has it changed over time?
Even after I’ve been steeped in something for a while — I’ve been writing software professionally for almost nine years, and as a student and an enthusiast for good while longer before that — questions will still sometimes pop into my head, and I’ll be driven to research them obsessively until I finally arrive at satisfactory answers. Often I’ll find myself revisiting some of the same questions again, months or years later, either because I’ve forgotten the details or because it turns out I wasn’t quite satisfied the first time.
Pull requests are ubiquitous in software development these days, yet I suspect that many developers — myself included, until recently — would struggle to define what a pull request actually is. If pressed, you might try explaining what you use them for: they facilitate code review; they signal the completion of some feature; they capture the context of a change for posterity. While helpful, to me these explanations don’t actually answer the question of what they are, fundamentally, and they certainly don’t explain why they’re called “pull requests.”
To really answer these questions thoroughly, we must understand the origin and evolution of pull requests. Given a cursory web search, you could be forgiven for thinking that pull requests were invented by GitHub as a convenience feature laid on top of (but not actually a part of) Git itself. You wouldn’t even be wrong, per se, but that’s not the whole story. Pull requests — after a fashion — have been a part of Git since the very beginning. Our tale begins even before that, however: no account of Git’s history would be complete without also touching on the history of Linux, for which Git was created in the first place.
The Old Ways: 1991 – 2002
In August of 1991, Linus Torvalds famously announced his “just a hobby” operating system project on Usenet. That project, of course, would soon be dubbed “Linux;” and in the thirty-plus years since, it’s become one of the most significant software projects in computing history, powering the vast majority of web servers; all Android smartphones; a wide variety of embedded devices; and of course the very computer on which this article was written.
The source control systems that existed at the time — most notably CVS and its predecessors, RCS and SCCS — were centralized systems, reliant upon a server to coordinate activity so that two people couldn’t edit the same file at the same time and risk conflicting changes. Appropriate, perhaps, for mainframe-UNIX from whence these tools came, but not for the massively parallel, massively distributed community that sprang up around Linux.
For the first decade or so, Linux didn’t use any formal source
control system at all. Instead, contributors would download a
tar archive of the source code for the most recent
release,2 copy it, then
make their changes in one copy and generate a comparison with the other
using the GNU diff utility. The output (referred to as a
patch) would then be sent by email to the
Linux Kernel Mailing List
(LKML), where the community could review and discuss the
changes — very much like what happens in the comments of a
GitHub-style pull request. Because the emails were plain text, and the
patches were sent inline as part of the email body, participants could
easily quote arbitrary bits of code in their replies for fine-grained
discussion.
If you’ve ever used Git from the terminal, the GNU
diff patch format should look strikingly familiar. As an
example, here is
a
small patch by Molnar Ingo from 1997, the earliest I could find that
still exists in the LKML archive:
--- 53c7,8xx.c.orig Sat Dec 6 08:14:24 1997
+++ 53c7,8xx.c Sat Dec 6 08:16:20 1997
@@ -3396,6 +3396,11 @@
NCR53c7x0_write8(STEST3_REG_800, STEST3_800_TE);
}
+static void private_kfree (void * addr)
+{
+ kfree(addr);
+}
+
/*
* Function static struct NCR53c7x0_cmd *allocate_cmd (Scsi_Cmnd *cmd)
*
@@ -3467,7 +3472,7 @@
#ifdef LINUX_1_2
tmp->free = ((void (*)(void *, int)) kfree_s);
#else
- tmp->free = ((void (*)(void *, int)) kfree);
+ tmp->free = ((void (*)(void *, int)) private_kfree);
#endif
save_flags (flags);
cli();Just like with Git, lines added to the original are marked with
+ and lines removed with -. Also like Git, the
changes are divided into “hunks,” each of which begins with
a header (@@ -3396,6 +3396,11 @@) that indicates the
position of the hunk in the original and updated files,
respectively.
Once a patch (or series of related patches) had passed general
review, the final version would be sent on to the maintainer in charge
of the relevant subsystem, and eventually on to Linus himself. Linus
would use diff’s counterpart, appropriately named
patch, to automatically apply the changes to his own copy
of the Linux code. (Importantly, anyone else in the community could do
the same if they wanted to test the changes, or benefit from them before
they were incorporated into a release.) The contributor side of this
process is described in
this
documentation, preserved via the very first Git commit of the Linux
codebase.
As both the code and the community grew, the
diff/patch workflow began to present some
problems. The more time elapsed — and the more patches
applied — since a given release, the more the code that contributors
were starting from diverged from the code that Linus had to integrate it
with, and the less likely it became that each successive patch could be
applied cleanly. That — combined with the sheer volume of patches
(and other traffic) flowing through the mailing list — meant a lot
of patches got dropped, often without comment as to why. If a patch was
important enough, the expectation was that eventually someone
(whether the original author or another interested party) would rework
it on top of the next release and submit it again. This was
sometimes
contentious.
In 1998, Larry McVoy founded a company called BitMover and proposed a solution:3 a new, distributed version control system which he later named BitKeeper.
The BitKeeper Controversy: 2002 – 2005
By 2002, BitKeeper had matured enough for Linus to start testing it out as part of his process. Most contributors continued to submit patches to the mailing list, but some — particularly the more senior maintainers — began keeping their work in BitKeeper repositories, updated more-or-less continuously from Linus’.
As already mentioned, BitKeeper is a distributed system — as is Git. Unlike CVS, where everything depends on a central server, every copy (or clone) of a BitKeeper repository is complete in and of itself. However, each clone maintains a relationship with its parent, from which it was cloned; changes can be synced between the two, with one repository either pulling from or pushing to the other. The process is described briefly in this documentation, which once again has survived via the very first Git commit of Linux.
This should all feel very familiar to Git practitioners, though of course there are differences. For instance, BitKeeper didn't have branches in the Git sense; instead, after cloning the repository from a remote server, you would make additional clones locally on your computer that you could use to keep different lines of development separate from one another. Git switches branches by replacing files within the same directory; with BitKeeper, you switched between your clones by navigating to other directories.
The big advantage of using BitKeeper was how it simplified the
process of integrating large numbers of patches. For one, the current
state of Linus’ repository (and that of other maintainers using
BitKeeper) was perpetually accessible over the web, which greatly
tightened up the “patch drift” problem. Secondly, it was no
longer necessary for Linus to take each patch and merge it himself: the
maintainers of each subsystem could handle merges for their own areas of
responsibility, and then Linus could simply bk pull the
changes from their repositories into his.
When a maintainer had code ready in a BitKeeper repository for Linus to pull it, they would send an email such as this 2003 example from Russell King:
Linus, please do a
bk pull bk://bk.arm.linux.org.uk/linux-2.5-pci
to include the latest PCI changes from Ivan Kokshaysky/myself. This will
update the following files:
arch/i386/pci/common.c | 15 +++
drivers/pci/pci.c | 48 ++++-----
drivers/pci/setup-bus.c | 235 ++++++++++++++++++++++++++++++++++++++++--------
drivers/pci/setup-res.c | 6 -
4 files changed, 239 insertions, 65 deletions
through these ChangeSets:
<ink@ru.rmk.(none)> (03/03/22 1.1133)
[PCI] Fix incorrect PCI cache line size assumptions.
Fix incorrect PCI cache line size assumptions on i386 and thus
avoid potential memory corruption with Memory Write-and-Invalidate.
<ink@ru.rmk.(none)> (03/03/22 1.1132)
[PCI] Make setup-bus.c aware of cardbus bridges.
Comments from rmk: …(Message truncated for brevity.) It seems only natural that such messages would come to be known as pull requests.
Didn’t you say controversy?
As much good as BitKeeper did for Linux’s development process, its adoption was a subject of recurring flame wars on the LKML. The problem was that, while BitKeeper was free (as in pizza) for use by members of the Linux community, it was not properly free software.
BitMover’s business model was designed to facilitate use by free-software projects at no cost, while retaining the ability to earn revenue from commercial customers. To that end, the no-cost version of the BitKeeper client logged changeset metadata publicly on the web. In theory, such public logging would be perfectly fine for free-software projects — whose development would be conducted in the open regardless — but unpalatable to businesses, who would be willing to pay for a version of the client that operated more privately.
Consequently, the license for no-cost use contained a number of restrictions: users were forbidden from doing anything to interfere with the logging, and if they had access to the source code (which was not guaranteed), they could only use or distribute derivative versions that still “[pass] all current regression tests for that version” and “[perform] Open Logging identically to a current or recent (less than one year old) version.” These might sound reasonable enough, but some argued otherwise. Perhaps most controversial was a non-compete clause, which forbade anyone from using BitKeeper if they also contributed to any other version control system.
Generally speaking, the BitKeeper license was acceptable to the “pragmatist” camp, including Linus himself; but not to the “free software idealist” camp. Unsurprisingly, Richard Stallman spoke out (well, wrote) against it more than once, and published a gloating I-told-you-so when Linux was later forced to move away from BitKeeper. Perhaps a little surprisingly, the Ohio State University Open Source Club submitted a formal petition to the LKML, arguing that Linux was “an important symbol of Open Source and Free Software” and that it was therefore inappropriate for core Linux developers to publicly promote the use of a proprietary system.
Larry McVoy could be a bit brusque when defending BitKeeper and its license, but he did also make some efforts to appease the critics. He maintained a CVS bridge, BK2CVS, that allowed contributors to track Linus’ main line of development using a CVS client instead of BitKeeper, albeit with some delay. Later, he announced a free-software client, although it was deliberately limited — it could only fetch the current state of a repository, with no access to its history, and Larry was very clear that he had no intention of changing that — and it came with a “No Whining License4” that, while perhaps intended as a joke, perhaps also illustrates the tension surrounding BitKeeper within the Linux community.
For better or for worse, the free client did not “(finally) put to rest any complaints about BK not being open source” as Larry hoped. Arguments continued; and in March 2005, Andrew “Tridge” Tridgell — who, aside from kernel development, was known for his work on Samba and rsync — created another, unauthorized free client called SourcePuller. While he claims it was never intended to replace BitKeeper, the idea was to allow people who wouldn’t or couldn’t use BitKeeper to access historical data in BitKeeper repositories — what Larry’s free client specifically did not do.
In April, Larry and Linus came to an agreement that BitKeeper was no longer a good fit for the Linux kernel. There were a few more new source control options in 2005 than there were in 1991 — Linus specifically named Monotone, another distributed system, as a candidate — but ultimately, Linus still wasn’t fully satisfied with any of them. Instead, he took a two-week period off from kernel work to lay down the foundations of Git.
Git Before GitHub: 2005 – 2008
Linus continued to be heavily involved in Git development for a few months before returning his full attention to the kernel and handing off maintainership of Git to Junio Hamano, who still leads the project to this day. Git was specifically designed to take the place of BitKeeper, so it should come as no surprise that the submission process was substantially similar.
Contributors continued to send patches via email to the LKML, where
the community would review them. I imagine that nearly all contributors
began adopting Git, seeing as it was properly free software and made it
easy to keep up with everyone else’s work; however, the patch
format remained essentially the same, so I suspect that if anyone really
didn’t want to bother with Git, they could continue to use the
older diff to generate their patches. Git was much more
convenient, though: once you made your commits locally, there were
built-in commands
(git
format-patch and
git
send-email) to convert them into a series of email messages
in the appropriate format. On the other end,
git
am5 extracted the
patches from the emails and reconstituted them into commits.
Maintainers who hosted their own Git repositories could also still
submit pull requests, as they had with BitKeeper. There was a command
for generating these, too:
git
request-pull, initially written
in
July 2005 by Ryan Anderson. The
format — again,
unsurprisingly — was very similar to the BitKeeper example
above: an introductory message; a link to the repository; a list of
commit subject lines, grouped by author; and an overall diffstat.
To generate this I used:
git request-pull origin x rsync://h4x0r5.com/git-ryan.git/
The git repository at:
rsync://h4x0r5.com/git-ryan.git/
contains the following changes since commit 154d3d2dd2656c23ea04e9d1c6dd4e576a7af6de
Ryan Anderson:
Add git-request-pull-script, a short script that generates a summary of pending changes
Make git-rename-script behave much better when faced with input contain Perl
Update the documentation for git-tag-script to reflect current behavior.
Add documentation for git-rename-script
Add support for directories to git-rename-script.
Documentation/git-rename-script.txt | 34 ++++++++++++++++
Documentation/git-tag-script.txt | 12 +++--
Makefile | 3 -
git-rename-script | 74 +++++++++++++++++++++++++++++++++---
git-request-pull-script | 36 +++++++++++++++++
5 files changed, 149 insertions(+), 10 deletions(-)Linux still uses this same development process today, as does Git itself.6
GitHub Arrives on the Scene: 2008 – 2011
GitHub
officially
launched in April 2008, though the site existed in beta for a few
months before that. In February, they
added
a pull request feature.7
The original version looked a lot like a GUI wrapper over git
request-pull — all it did was send a notification to one or
more other users. The notification listed the repository and head commit
to pull from, sported a link to view the commits involved, and had space
for an optional short message. It was then up to the recipients to pull
the commits manually; per the example in
the
documentation:
git remote add defunkt git://github.com/defunkt/grit.git
git checkout -b defunkt/master
git pull defunkt master:4f0ea0c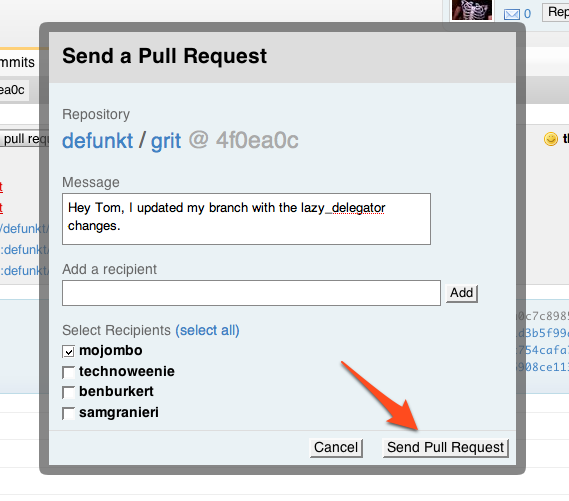
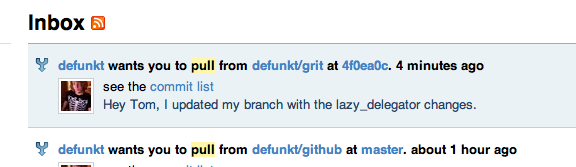
Later that year, they added an auto-responder for cases where someone is either unable (e.g. on vacation) or unwilling to accept pull requests through GitHub. Aside from that, the pull request experience remained essentially unchanged for the next two years.
In August 2010, GitHub launched “Pull Reqeusts 2.0,” radically transforming them into essentially what we’re familiar with today (emphasis in the original):
Now we’re taking it to the next level with a re-imagined design and a slew of new tools that streamline the process of discussing, reviewing, and managing changes.
As of today, pull requests are living discussions about the code you want merged. They’re our take on code review and represent a big part of our vision for collaborative development.
The revamped submission screen was a full page instead of a modal dialog, and it now had space for a user-entered subject line. The message text box was much larger, and supported Markdown formatting. There were also tabs where you could see the commits that would be included and the overall diff. The only really noticeable difference from today’s version — aside from the CSS — is that there was still a list of the people who would receive notifications when the pull request was submitted.
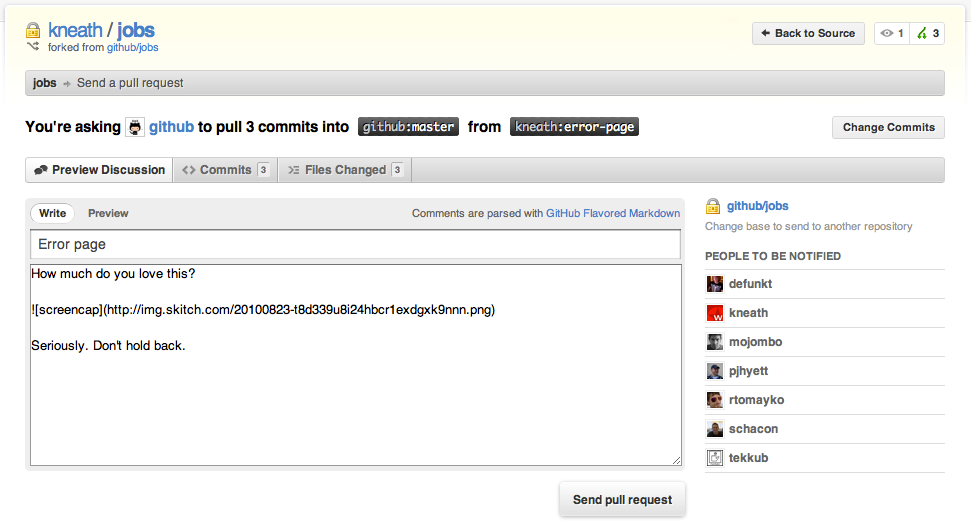
Pull requests went from ephemeral notifications — existing temporarily, and only in the inboxes of their recipients — to permanent, public records, immortalizing the discussion surrounding each contribution and tracking any further changes that emerged from said discussion.
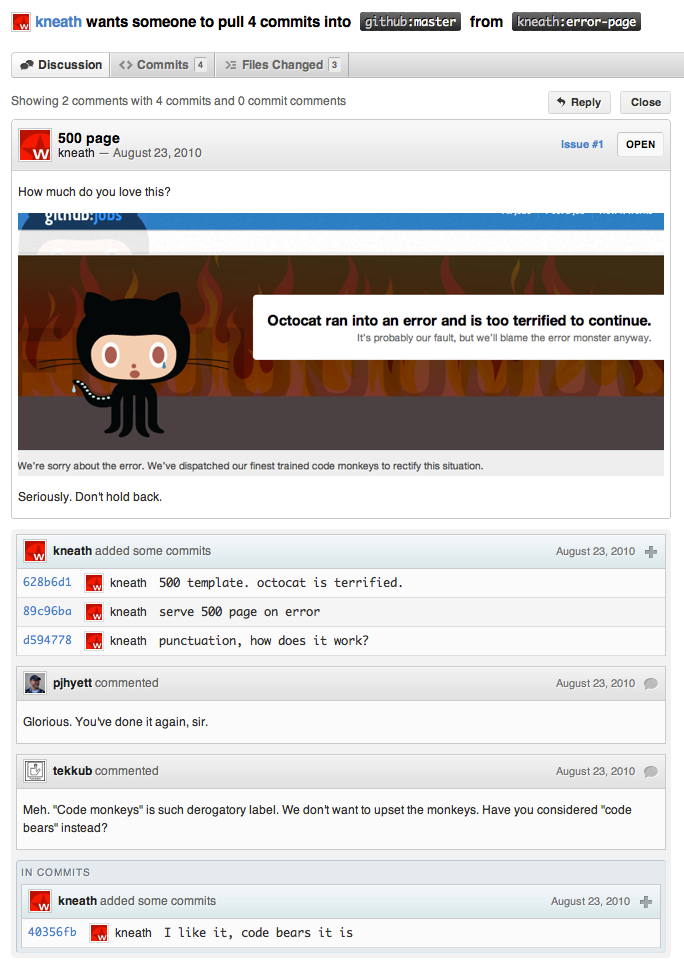
In February 2011, GitHub added the ability to comment directly in a pull request’s diff view — finally permitting the style of fine-grained review seen in the LKML for the past twenty years.8
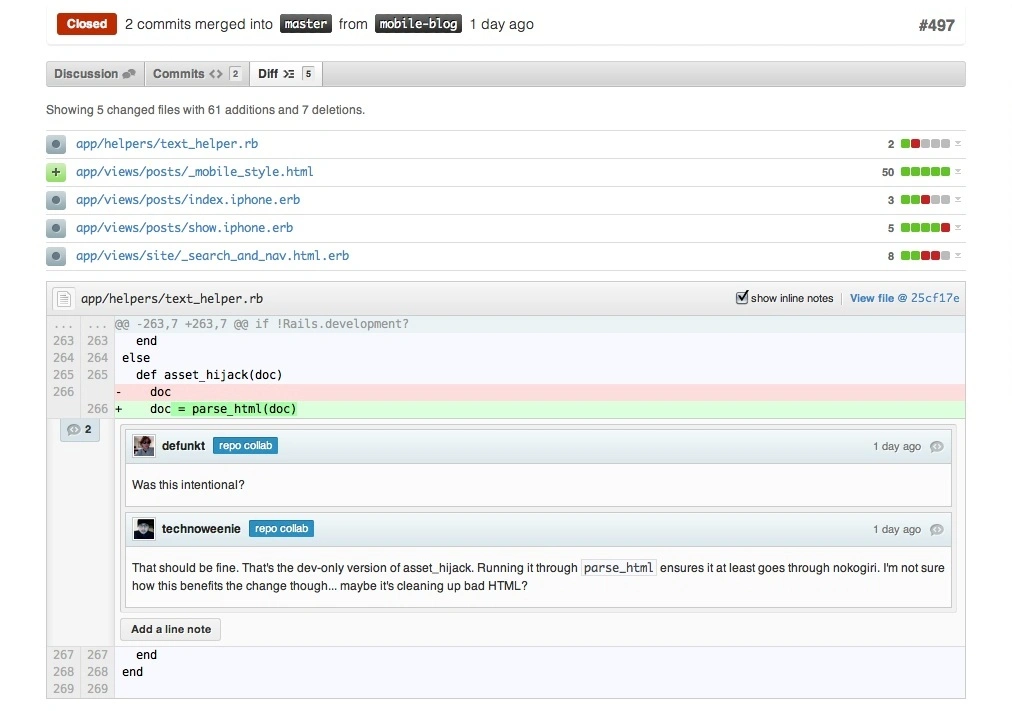
Interestingly, people still had to merge pull requests manually this entire time. That didn’t change until April 2011, which saw the first appearance of the “long anticipated” merge button.
Diaspora: 2011 – Present
I wanted to wrap up this post by tracing the adoption of GitHub-style pull requests across other source code hosting platforms (or software forges, as some call them), but it turns out there are/have been rather more of those than I would have guessed — CodePlex (defunct), Google Code (defunct), SourceForge (surprisingly, not defunct), Bitbucket, GNU Savannah, Phabricator (defunct), Launchpad, GitLab, Gitea, and that’s not even all the ones I’d heard of before — and, frankly, I kinda ran out of steam on the research front. This section is consequently less thorough than I might have liked, but you at least get the idea.
As of mid-2011, it seems like GitHub’s main rivals were SourceForge, Bitbucket, Google Code, and CodePlex. As already mentioned, Google Code and CodePlex have both been discontinued,9 and I didn’t try very hard to dig up the chronology of their feature sets.
Bitbucket launched in 2008, the same as GitHub; only instead of Git,
it focused on
Mercurial — which
was also created starting in April of 2005 as a potential
replacement for BitKeeper. Bitbucket added support for Git
on
April 1st, 2009
in October
2011, a few months after implementing
GitHub-esque pull requests for Mercurial (I assume Git repositories,
when they became available, had access to the same features). More
recently, in 2020, Bitbucket dropped
support for Mercurial to focus exclusively on Git, citing
Git’s overwhelming popularity and the difficulty of making sure
that new features and other improvements remained compatible with both
systems.
SourceForge is much older: it launched in 1999, offering only CVS at first and adding Subversion in 2006. Alas, SourceForge’s blog archive is rather less helpful than GitHub’s or Bitbucket’s in terms of feature history, so the best I can tell you is that they added Git support (and Mercurial, and Bazaar) sometime between this 2006 snapshot of their service listing and this 2009 snapshot of a similar page, both courtesy of the Internet Archive. I gave up trying to find more specifics about their “merge request” feature (as they call it), but even today it’s closer to GitHub’s pull request 1.0 than 2.0 (albeit with a single discussion thread and a merge button).
Microsoft’s Azure DevOps Services (formerly Visual Studio Team Services, formerly Visual Studio Online, formerly Team Foundation Service) began life as a hosted platform in 2012, though the same software had been available for companies to self-host since 2005 and was closely related to CodePlex. It originally supported only Team Foundation Version Control (TFVC), a centralized system, but it added Git support in 2013 and gained GitHub-style pull requests by mid-2014.
GitLab began in 2011 as an open-source alternative to GitHub — which, despite its raison d’être of hosting free and open-source projects, is itself notoriously proprietary. They added merge requests a month later, in November 2011. GitLab Inc., the company that now oversees continued developoment of the GitLab software and provides the hosted instance at gitlab.com, launched four years later in 2014.
Codeberg launched in 2019 as a German non-profit offering GitHub-esque services powered by the open-source Gitea project. Gitea forked in 2016 from an older project called Gogs, citing frustration with Gogs’ maintainer. Gogs got started in 2014 and added pull requests in 2015. Last year, the stewards of Gitea unexpectedly transferred ownership of the Gitea trademark and gitea.com domain to a newly-formed for-profit company, Gitea Ltd., apparently in hopes of securing a more consistent revenue stream to fund Gitea development. Nonetheless, and despite assurances, a significant portion of the Gitea community found the move discomfiting and ultimately started another fork, Forgejo, under the auspices of the Codeberg non-profit (and Codeberg now runs Forgejo instead).
One very notable exception to the trend is SourceHut. While most of the other services described above either launched with or adopted pull requests (and other UI elements) based on GitHub’s example, SourceHut — launched in 2018 — instead asks what it would look like for a modern service to embrace the email-based workflow that Git was designed for. The result is something that I, personally, find very intriguing — but that is, perhaps, a subject for another time.
Footnotes
For the record, I wrote this paragraph months before a certain website changed its name. The term “x” here is meant exclusively in the algebraic sense. ↩︎
I wanted to exclusively link LKML messages via the official archive at lore.kernel.org/lkml, but for whatever reason this message seems to be missing there. I only found it because of the references list on the BitKeeper Wikipedia page. ↩︎
↩︎/* * tarball.c copyright (c) 2003 BitMover, Inc. * * Licensed under the NWL - No Whining License. * * You may use this, modify this, redistribute this provided you agree: * - not to whine about this product or any other products from BitMover, Inc. * - that there is no warranty of any kind. * - retain this copyright in full. */git amis short for “apply mbox,” where mbox is a common file format for email messages.git amactually replaced an older command namedgit applymboxin October 2005. ↩︎- In 2015, Johannes Schindelin (leader of the Git for Windows project) started work on a tool called GitGitGadget that takes GitHub pull requests and converts them into an email series on the Git mailing list. This makes it easier for new or transient contributors to get involved, while still allowing the veterans to keep using the tools and workflow they’re accustomed to. The Linux community has also considered doing something similar. ↩︎
My research for this article began here. Originally, I thought that finding a blog post about the introduction of pull requests to GitHub would give me a definitive answer regarding the origin of the concept. Instead, the nonchalant nature of the announcement — “Oh yeah, there’s pull requests now” — seemed to imply it was something their readers would already be familiar with, rather than a novel extension atop Git as I had believed. I went backwards from there, first finding the origin of
git request-pullon the Git mailing list, and then scouring the LKML to understand how Git had been influenced by BitKeeper. ↩︎And, I’m sure, plenty of other free-software mailing lists before that. ↩︎
It seems notable that Microsoft shuttered CodePlex in 2017, stating that “GitHub [had become] the de facto place for open source sharing and most open source projects [had] migrated there,” and then they went and bought GitHub one year later. ↩︎